![]()
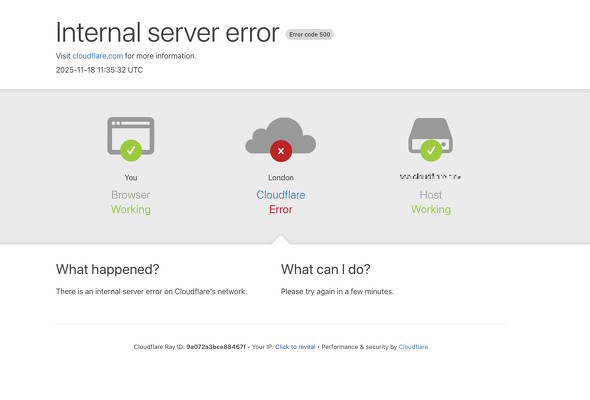
11月18日、「X(旧Twitter)」や「ChatGPT」など複数のインターネットサービスにおいて、世界規模の障害が発生した。この障害は、早々に「Cloudflare(クラウドフレア)」のCDN(Contents Delivery Network)サービスが原因であることが判明した。CloudflareはCDNサービスの最大手事業者だけに、その影響は非常に大きくなった。
Cloudflareのマシュー・プリンスCEOは同日、この障害が「ソフトウェアの問題(バグ)が引き起こした想定外の動作により、ソフトウェアが停止したこと」が原因である旨をブログで明らかにした。
インターネット経由でサービスを提供する企業の多くは、クラウドベースの「SaaS(Software as a Service)」「IaaS(Infrastructure as a Service)」など、クラウドサービス事業者(CSP)のサービスに依存している。そのため、CSPのサービスが停止すると自社のサービスも停止するという依存関係にある。
「ネットにつないでなければ大丈夫でしょ?」と思うかもしれない。しかし、WindowsやmacOSで稼働するローカルアプリでも、最近はライセンス(利用許諾)の確認でインターネット接続が必要なものがある。そのため、ローカルアプリでもCSPのサービスに障害があると動作に影響が生じるケースがある。
|
|
|
|
詳細な原因は調査中だが、11月18日に発生したmacOS版の「Adobe Creative Cloud」関連アプリのトラブルも、状況的にCSPサービスの障害が原因の可能性もある。
この記事では、これらの事象について解説をする。
●「CDN」ってそもそも何?
CloudflareのようなCDNサービスは、ざっくりいうと同じデータを持つサーバを“物理的”に分散配置することで、1つのサーバにアクセスが集中することを防ぐサービスだ。
もう少し具体的にいうと、CDNは大本となるサーバと常時同期するキャッシュサーバが複数用意される。キャッシュサーバは国/地域単位で分散配置され、データのやり取りをリクエストした端末が大本のサーバにアクセスしようとすると、CDNサービスはキャッシュサーバにアクセスを“誘導”する。
|
|
|
|
サービスの提供者側には1つのサーバにアクセスが集中すること負荷を軽減できるというメリットがあり、利用者側も近くのキャッシュサーバにアクセスすることで応答速度(レスポンス)が向上するというメリットを享受できる。
例えば「誰もが行きたいと思うようなコンサートのチケット」「割引率が高いセール商品」などが販売されるとき、多くの人が買いたいと思い、販売サイトにアクセスが殺到する。そうすると、Webサーバがリクエストをさばききれなくなって、極端にレスポンスが悪くなったり、最悪の場合は落ちてしまったりする――インターネットで良く聞くインシデントの1つだ。
「Webサーバにアクセスが集中して落ちる」という現象は、別にユーザーのアクセス集中だけが原因とは限らない。Webサーバを攻撃する古典的な手法として知られている「DDoS(Distributed Denial of Service:分散型サービス妨害)」は、攻撃者のクライアントから多数のアクセスが発生するため、アクセス集中と同じような結果(=Webサーバのダウン)をもたらす。
こうしたDDoSを防ぐのにも、CDNは役立つ。アクセスが集中する可能性があるインターネットサービスでは、CDNサービスを利用するのが一般的だ。
CDNはどうやってキャッシュサーバにアクセスを誘導する?
|
|
|
|
通常、ユーザーがWebサーバにアクセスする場合、WebブラウザのURL欄に「https://www.itmedia.co.jp/」といったアドレスを文字列として入力する。すると、Webブラウザはその裏側で、インターネットの基本的な仕組みである「DNS(Domain Name System)」という機能を利用して、アクセス先のWebサーバの「IPアドレス」をDNSを保管している「DNSサーバ」から引っ張ってきて、そのIPアドレスに向かってアクセスを要求する。
CloudflareなどのCDNサービスは、クライアントからこうしたアクセス要求を受けると、必要に応じてデータをキャッシュしたCDNサーバのIPアドレスを返すことでアクセスを振り分ける。これにより、1つのサーバに集中してしまうことを防いでいる。
●Cloudflareのダウン原因は「バグ」 しかし「バグ」は排除しきれない
今回のインシデントは、そのCloudflareが提供しているCDNのサービスがそのものが落ちてしまったため、クライアントからキャッシュサーバへのアクセスができなくなり、Cloudflareを利用しているXやOpenAIなどのサービスにアクセスができなくなったということだ。
今回、CloudflareのCDNが落ちてしまったのはなぜなのか――先述の通り、Cloudflareは既に原因を特定し、CEO自らが詳細にブログで説明している。
このブログエントリーの中で、プリンスCEOは原因を以下のように説明している。
この問題はサイバー攻撃や悪意のある行為によるものではなく、当社の行ったデータベースシステムに対する権限変更に起因するものであり、ボット管理システムで使用される「フィーチャーファイル」に複数のエントリが出力され、ファイルサイズが予想以上に倍増したことでした。大きくなったフィーチャーファイルは、ネットワークを構成する全ての機器へと伝播されました。伝播先の機器上で動作するネットワーク全体のトラフィックをルーティングするソフトウェアは通常、このフィーチャーファイルを読み込んでボット管理システムを最新の状態に維持することで常に変化する脅威に対応しますが、伝播されたフィーチャーファイルのサイズがソフトウェアで設けられているファイルサイズの上限を超えており、結果、ソフトウェアが正しく機能しなくなる事態へと繋がりました。
非常にざっくりいえば、同社が「ボット管理システム」と呼んでいる設定ファイルのコピーに同社が利用しているサードパーティツールの問題からエラーが発生し、通常の設定ファイルに比べて倍のファイル容量になり、ソフトウェアに設定されているファイルサイズの上限を超えてしまった結果、システムがダウンしてしまったということのようだ。
今回の事案で“不運”が重なったこととして、Cloudflareの調査チームは当初、DDoS攻撃の可能性を疑い、それを前提に調査を続けたため、結果としてソフトウェアのバグであることを突き止めるのに5時間近い時間がかってしまい、復旧までに通常より時間がかかったのだという。
こうしたソフトウェアのバグを起因とするインシデントは、別にCloudflareでのみ発生する訳ではない。「完璧なものは存在せず、完璧に見えるものはまだバグが発見されていないだけ」というソフトウェアの特性を考えると、どんなソフトウェアでも、もっといえばどんなクラウドサービスでも起こりうる。
●これからのWebサービス提供者に必要なのは「BCP」
クラウド経由で提供されているSaaSに関するインシデントは、10月にもAmazon Web Servicers(AWS)でも発生している。
AWSの場合は、米国の主要な拠点となる北バージニアにある「US-EAST-1」で発生した障害が顧客企業にも波及した形になる。
AWSはSaaSだけでなくIaaSとして仮想ハードウェアの提供も行っている。US-EAST-1はAWSの主力中の注力の拠点の1つとなっており、AWSでSaaS/IaaSを利用する企業に大きな影響が発生した。
現在は、昔ながらの「オンプレミス(自社内運用)サーバ」だけでサービスを提供している大企業というのはほとんどない状況だ。AWSやCloudflareのようなSaaS、あるいはAWS/Google Cloud/Microsoft AzureなどのIaaSを利用してソフトウェアやITのインフラを構築している事業者の方が多い。結果として、仮にSaaSやIaaSなどに問題が発生した場合、サービスの継続が困難になることが多いのが現状だ。
ただ、SaaS/IaaSを利用している全ての企業で問題が発生している訳ではない。CSPのサービス拠点(AWSなら「リージョン」と呼ぶ)を複数利用する契約を締結し、どこかで問題が発生しても別の拠点でバックアップを立ち上げてサービスを継続できるようにしている企業も多い。
その意味では、CloudflareやAWSの障害時でもサービスを止めることがなかった企業は、サービスのBCP(Business Continuity Plan:事業継続計画)がうまく行っていると見てよいだろう。
●ローカルアプリでもCSPの障害の影響を受けうる
11月18日、macOS版Adobe Creative Cloudを構成する一部アプリにおいて「アプリが起動しない」「ファイルを読み込めない」「キーボード入力できない」といった不具合が発生した。この問題は解消済みだ。
先述の通り、本件の原因の詳細は調査中だが、状況的にCSPサービスの障害が原因である可能性がある。というのも、オフラインで起動すると、問題がほとんど起こらなくなったからだ。
このように、今やローカルアプリであってもインターネットで常時通信しているものが多い。もっというと、「PWA(プログレッシブウェブアプリ)」の仕組みを使ってWebブラウザを内部で呼び出して、Webページと同じ仕組みで表示しているだけというものもある。
PWAによるアプリの代表例が、Microsoft Storeで配信されている新しい「Microsoft Outlook」だ。新しいOutlookアプリは、インターネットがない環境ではそもそも起動できない。筆者が飛行機の中でPCを再起動した後、「オフラインでメールの履歴を見たいと思って」Outlookを起動しようとしたら、インターネットに接続していないと起動してくれなくて困ったことがある。
その意味では、ユーザー自身のBCPを考えると頭が痛い状況だ。ただし、先述のOutlookの場合、Microsoft 365やMicrosoft Officeに内包されているClassic版はオフラインでも利用できる。しばらくは、Classic版を使って様子を見るというのが手っ取り早い解決策である。
いずれにせよ、インターネットというのは基本的にベストエフォート(最善の努力でサービスを提供するが稼働保証はないということ)であり、より平易な日本語で言えば「つながったらラッキー」というものであることが前提だ。
その意味では、常にバックアップのツールを用意しておくことも大事なのではないだろうか。例えば「Premiere ProがダメならDaVinci Resolveがあるさ」というのは極論だが、業務利用ではなかなか自由が利かないというのもあるだろう。
とはいえ、法人/個人を問わず、普段利用しているアプリやサービスが止まった場合を事前に相談/検討しておくにこしたことはなさそうだ。
![]()
|
|
|
|
|
|
|
|
Copyright(C) 2026 ITmedia Inc. All rights reserved. 記事・写真の無断転載を禁じます。
掲載情報の著作権は提供元企業に帰属します。
IT・インターネット
ランキング IT・インターネット
IT・インターネット
アクセス数ランキング
- 1

購入制限、ジャパネット対応話題(写真:ねとらぼ)83
話題数ランキング
- 1

Suicaの利便性、さらに高まる?(写真:ITmedia Mobile)101