限定公開( 1 )
![]()
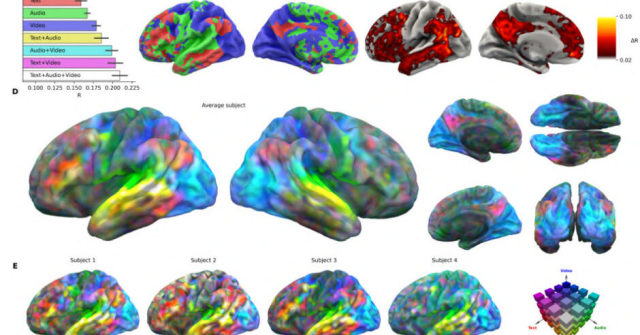
米Metaなどに所属する研究者らが発表した論文「A foundation model of vision, audition, and language for in-silico neuroscience」は、人間の脳活動を予測する基盤モデル「TRIBE v2」を発表した研究報告だ。
従来の脳科学では「顔を見るときはこの部位が活発になる」といったように、顔認識や言語処理など個別の機能ごとに対応する脳部位を調べるのが主流だった。しかし、日常的には複数の感覚が同時に働いているのが人間の脳だ。TRIBE v2はこの複雑な脳活動に対し、動画・音声・テキストという3つの情報を統合して、それらを見聞きした際に脳がどう反応するかをシミュレーションする。
これまでは脳の反応を調べるには、人間をfMRI装置に入れて測定するのが常識だった。しかしTRIBE v2は、720人分・1000時間以上のfMRI脳データを学習しており、「インシリコ実験」──すなわち生身の人間やfMRIを一切使わずに、コンピュータ上だけで脳科学の実験を成立させられる。
例えば、顔の画像を見せたときに反応する「紡錘状回顔領域」や、文字を見たときに活発になる「視覚的単語形状領域」、他にも身体や場所などといった数十年にわたる実証研究で特定されてきた脳の局所的な反応を、AIの予測だけでほぼ正確に再現できた。加えて、複数の感覚が脳内でどのように統合されるかというメカニズムまでも可視化している。
|
|
|
|
その結果、従来の線形モデルを大幅に上回る精度を達成し、未知の動画や音声、さらには一度もデータとして取り込んだことのない新規被験者に対しても、脳の反応を予測できるようになった。国際コンペ「Algonauts 2025」では263チーム中1位を獲得している。
ただし制約もある。fMRIの性能(時間分解能)の限界から、ミリ秒単位の神経活動は捉えられない。入力も視覚・聴覚・言語に限られるため、嗅覚や触覚などの感覚は扱えない。さらに、脳を刺激の受動的な受け手としてのみモデル化しており、行動の生成や意思決定、発達過程、臨床的な病態といった能動的・動的な側面にはまだ対応できていない。
一方で、データ量と精度の間にスケーリング則が確認されており、今後さらに大規模なfMRIデータが集まれば予測精度がさらに向上する可能性がある。
TRIBE v2をプラットフォーマーとしてのMetaから見ると、ある動画をユーザーが視聴した際に脳のどの領域がどう活性化するかを“配信前”に把握できるという点が注目に値するという。つまり、動画を公開する前に、その映像が人々の感情をどう揺さぶるかを脳科学の観点からシミュレーションできるわけだ。
MetaはSNSを長年運営しているため、人々の反応データ(エンゲージメント指標、画面の滞在時間など)を膨大に保持しており、それらをターゲティング広告などに活用してきた。そこに今回の脳反応予測が加わることで、ユーザーの反応をより根本的なレベルから予測・最適化していく道が開けるかもしれない。
|
|
|
|
![]()
|
|
|
|
|
|
|
|
Copyright(C) 2026 ITmedia Inc. All rights reserved. 記事・写真の無断転載を禁じます。
掲載情報の著作権は提供元企業に帰属します。
IT・インターネット
ランキング IT・インターネット
IT・インターネット
アクセス数ランキング
- 1
4.1に嘘の新聞紙面投稿で謝罪文(写真:ITmedia NEWS)78
話題数ランキング
- 1
4.1に嘘の新聞紙面投稿で謝罪文(写真:ITmedia NEWS)78